New features after a week of testing: speaker diarisation and more
Over the past week I've been testing Murmel with podcast makers, cultural organisations, universities, NGOs, and civil servants. Those conversations consistently produce concrete insights: what's working well, what's missing, and what would be most valuable to build next.
Based on that feedback, several new features have been added to Murmel.
Speaker diarisation
The most-requested feature is now available. Murmel automatically detects who is speaking and labels each line by speaker. So you don't just see what was said, but also by whom.
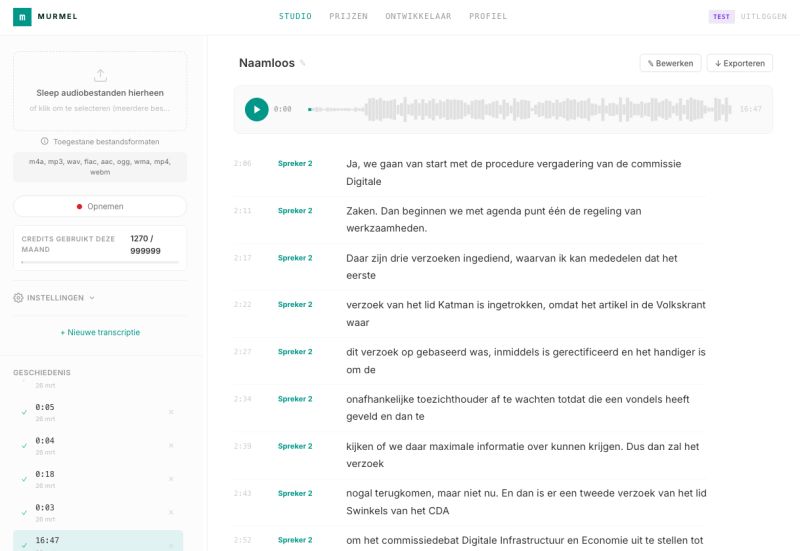
Murmel Studio shows each line per speaker, with timestamps at word and segment level.
This is especially useful for meetings, interviews, and debates. Instead of one long block of text, you immediately see the structure of the conversation in the transcript.
Accessibility
We've taken the first steps toward making Murmel more usable for people who rely on screen readers. The interface now has semantic HTML, proper ARIA labels, and full keyboard navigation. This is an ongoing effort, but the foundation is in place.
Infrastructure on Leafcloud
Murmel runs on Leafcloud's GPU servers in Amsterdam. Current processing speed is 37 times realtime. A one-hour recording is fully transcribed in under two minutes.
Leafcloud places their servers inside residential buildings and uses the residual heat to warm homes and provide hot showers, directly replacing natural gas. It's infrastructure we're proud to be working with.
Want to test it?
There's a free tier available with 60 minutes of transcription per month, no credit card required. Sign up at app.murmel.eu.
If you're working with larger volumes of audio, or want to integrate Murmel via the API, get in touch and we'll figure out what fits best.