Murmel is coming: the platform and API are launching soon
Last week I introduced Murmel, a Dutch speech-to-text model trained in the Netherlands that beats every open-source alternative on Dutch audio.
Over a hundred reactions, dozens of messages, and organisations from municipalities to universities to government ministries reaching out to test it. Clearly, the Netherlands has been waiting for a model that actually takes Dutch seriously.
Today I want to share what's next: the platform I have been building around Murmel, and how you can start using it.
From model to product
A great model is only half the work. To make Murmel actually useful, it needs an interface, an API, proper infrastructure, and all the essential things: authentication, usage tracking, documentation, and data governance you can trust.
It’s nearly ready: a complete Dutch transcription platform.
The Murmel web interface
The simplest way to use Murmel is through the web interface. Upload your audio file and get a transcript back. No installation, no configuration, no technical knowledge required.
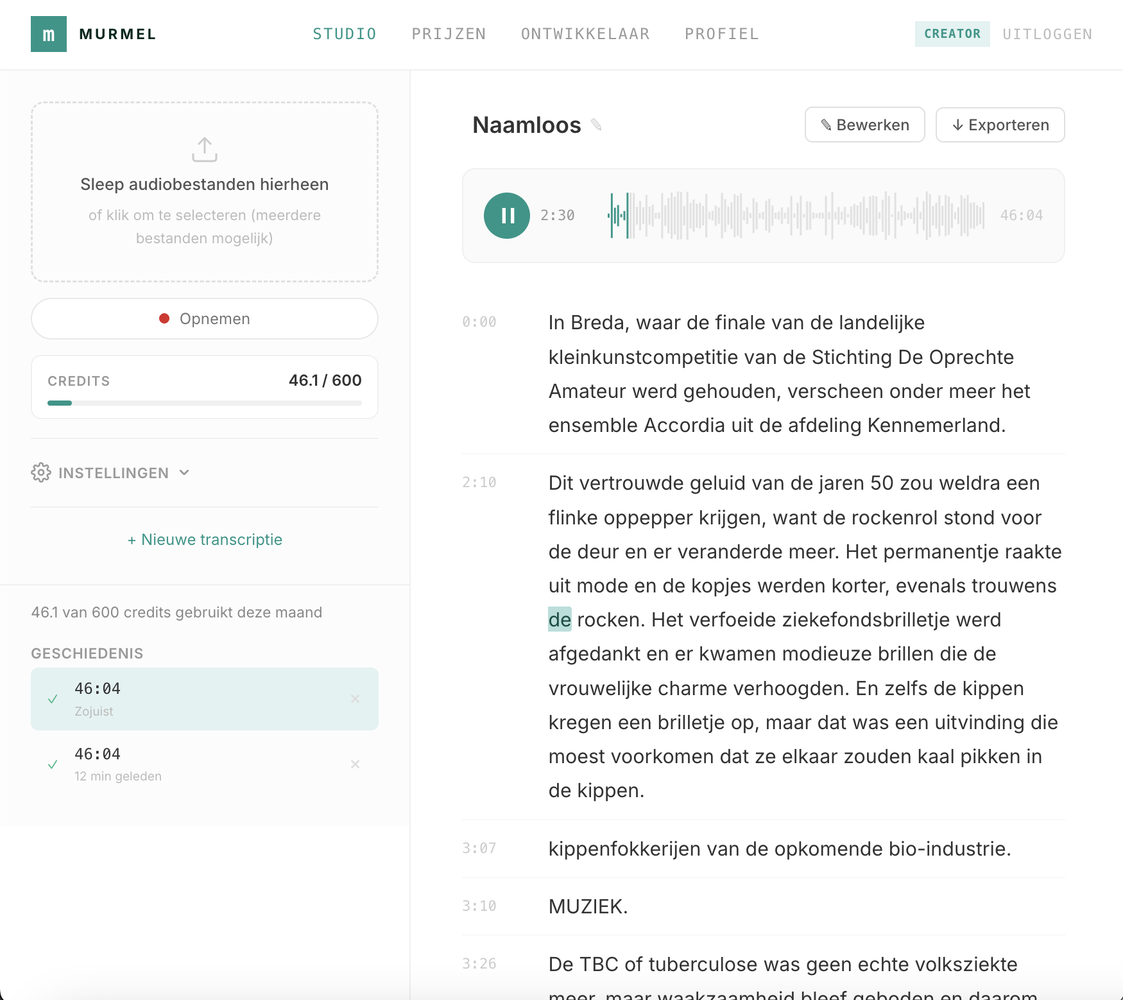
The interface supports all common audio formats: WAV, MP3, M4A, WEBM, OGG, FLAC, and more. Whether you're transcribing a meeting recording from your phone or a high-quality studio file, it just works.
You can read the transcript in the interface, or export it in any of the formats shown below (TXT, SRT, VTT, RTF, PDF, JSON, CSV)
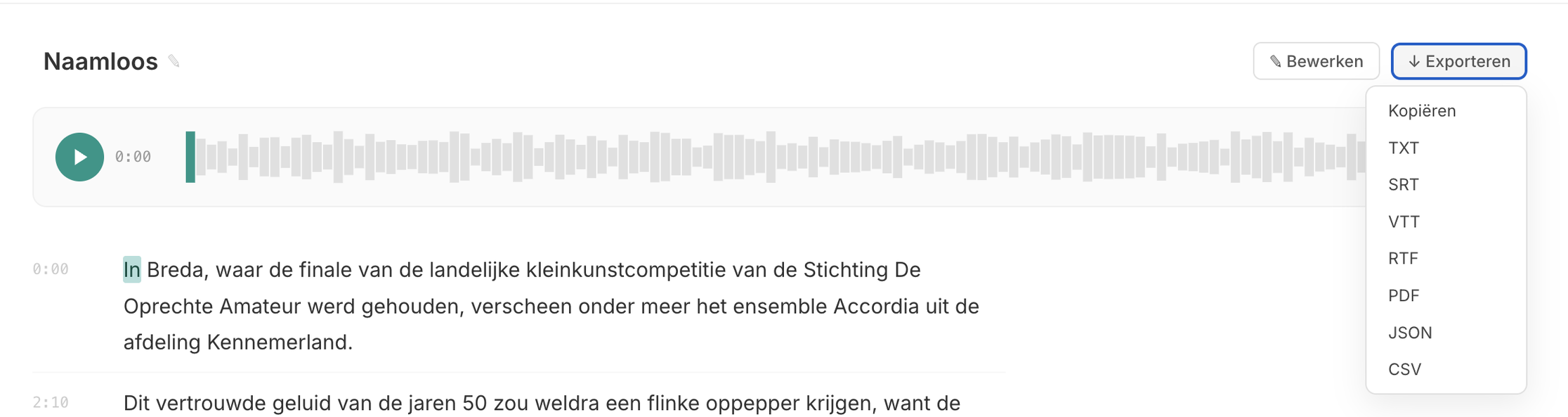
For organisations that need to transcribe audio but don't have a development team, this is the fastest path. Upload your file, read the result, copy the text. Done. Murmel is available in a way so that anyone in your organisation can use it, not just the IT department.
The REST API
For developers and teams that want to integrate Dutch transcription into their own systems, Murmel comes with a fully documented REST API.
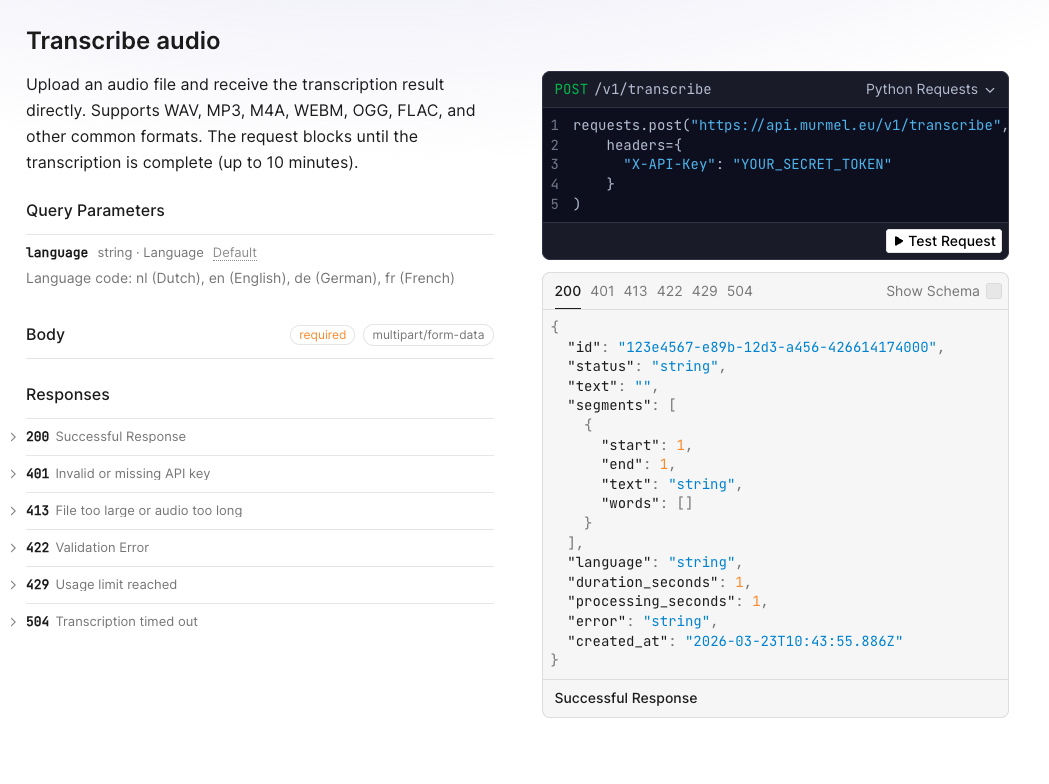
The API is straightforward, you send the audio and get the transcription back. Endpoints for usage tracking, transcription history, and language support. All documented with interactive examples.
Typical use cases we're already seeing interest in:
- Simple usage: Upload a file and get a transcript
- Automated pipelines: Council meeting recordings automatically transcribed after each session
- Application integration: Adding transcription as a feature inside existing software
- Batch processing: Transcribing archives of recordings at scale
- Quality assurance: Cross-checking existing transcriptions against Murmel's output
The API is designed for production workloads. It handles large files (up to 500 MB), returns word-level timestamps for precise alignment, and supports synchronous transcription: you send the audio, and the response comes back with the transcript.
The Python SDK
For the fastest integration path, we've published a Python SDK. Install it with pip and you're writing code in minutes:
from murmel import Murmel
client = Murmel(api_key="murmel_sk_...")
# Transcribe an audio file
result = client.transcribe("meeting.mp3")
print(result.text)Three lines to go from audio file to transcript. The SDK handles authentication, file uploads, error handling, and retries. It's available on PyPI: pip install murmel.
For teams building transcription into their applications, this means you can have a working prototype in an afternoon, not a sprint.
Hosted 100% in the Netherlands
This is where Murmel is fundamentally different from the alternatives.
All audio processing, all storage, and all model inference runs on infrastructure hosted entirely in the Netherlands. Your audio data never leaves the country.
For many organisations, this isn't a preference. It's a requirement. The EU AI Act is introducing new obligations for AI systems that process personal data. GDPR already requires careful consideration of where and how audio data is processed. If you're transcribing council meetings, medical consultations, legal proceedings, or HR interviews, the question "where does my audio go?" needs a clear answer.
With Murmel, the answer is simple: the Netherlands. Full stop.
And there's more. By default, your data is never used for model training. Audio and transcriptions are automatically deleted after 7 days, or sooner if you choose. You stay in full control of your data at all times.
This isn't a footnote in Murmel's terms of service. It's a core design principle. I believe you should be able to use AI transcription without compromising on data governance, and I built Murmel to prove that's possible.
Murmel is currently being tested by the first users, and looking for more partners
I am currently running tests with our first partners, and the early results are encouraging. Murmel is performing well on real-world audio, and the infrastructure is being optimised.
But I want to go further. I want to understand how Murmel performs on every type of Dutch audio, in every domain, with every kind of speaker.
That's why I'm looking for more testing partners.
If you're working with Dutch audio, I want to hear from you. Send a message with what you want to use it for, and get transcription credits in exchange for honest feedback on the quality. Whether you're dealing with:
- 🏛️ Council meetings (gemeenteraadsvergaderingen, commissievergaderingen)
- ⚕️ Medical consultations and patient recordings
- ⚖️ Legal proceedings and court recordings
- 📞 Call centre conversations
- 🎙️ Interviews, podcasts, or journalism
- 🏢 Internal meetings and presentations
- 📚 Educational recordings or lectures
...reach out, and I will set you up with access to the platform and API. No commitment, no strings attached. I just want to make the model better through real-world feedback.
What's next
The platform launches soon.
The focus from here is on making Murmel a product you can rely on. That means making it safe: clear data governance and infrastructure you can trust with sensitive audio. It means making it easy: a clean interface, a well-documented API, and integrations that work without friction. And it means making it fast: as I onboard more customers, I will be investing in speed and throughput so Murmel scales with your workload. The tech stack is built for that from the ground up.
On the model side, speaker diarization (who said what) is in active development and will be one of the first features to be added
Join the waitlist
Sign up at the-ai-factory.com/murmel to get early access to the interface and API before we launch.
Or reach out directly if your organisation has Dutch audio that needs transcribing.
Murmel is built in the Netherlands 🇳🇱, hosted in the Netherlands, and built for organisations that need Dutch done right.