Murmel komt er aan
Vorige week introduceerde ik Murmel, een Nederlands spraak-naar-tekst model gehost en getraind in Nederland, dat elk open-source alternatief verslaat op Nederlandse audio.
We ontvingen ruim honderd reacties, tientallen berichten en organisaties – van gemeenten tot universiteiten en ministeries – die contact opnamen om het te testen. Het is duidelijk dat Nederland heeft gewacht op een model dat de Nederlandse taal wél serieus neemt.
Vandaag deel ik wat de volgende stap is: het platform dat ik rondom Murmel heb gebouwd, en hoe je het kunt gaan gebruiken.
Van model naar product
Een geweldig model is slechts het halve werk. Om Murmel daadwerkelijk bruikbaar te maken, heeft het een interface, een API, degelijke infrastructuur en alle essentiële zaken nodig: authenticatie, usage tracking, documentatie, en databeveiliging (data governance) waar je op kunt vertrouwen.
Het is bijna zover: een compleet Nederlands transcriptie platform.
De Murmel web interface
De eenvoudigste manier om Murmel te gebruiken is via de web interface. Upload simpelweg je audiobestand en je krijgt een transcriptie terug. Geen installatie, geen ingewikkelde configuratie en geen technische kennis vereist.
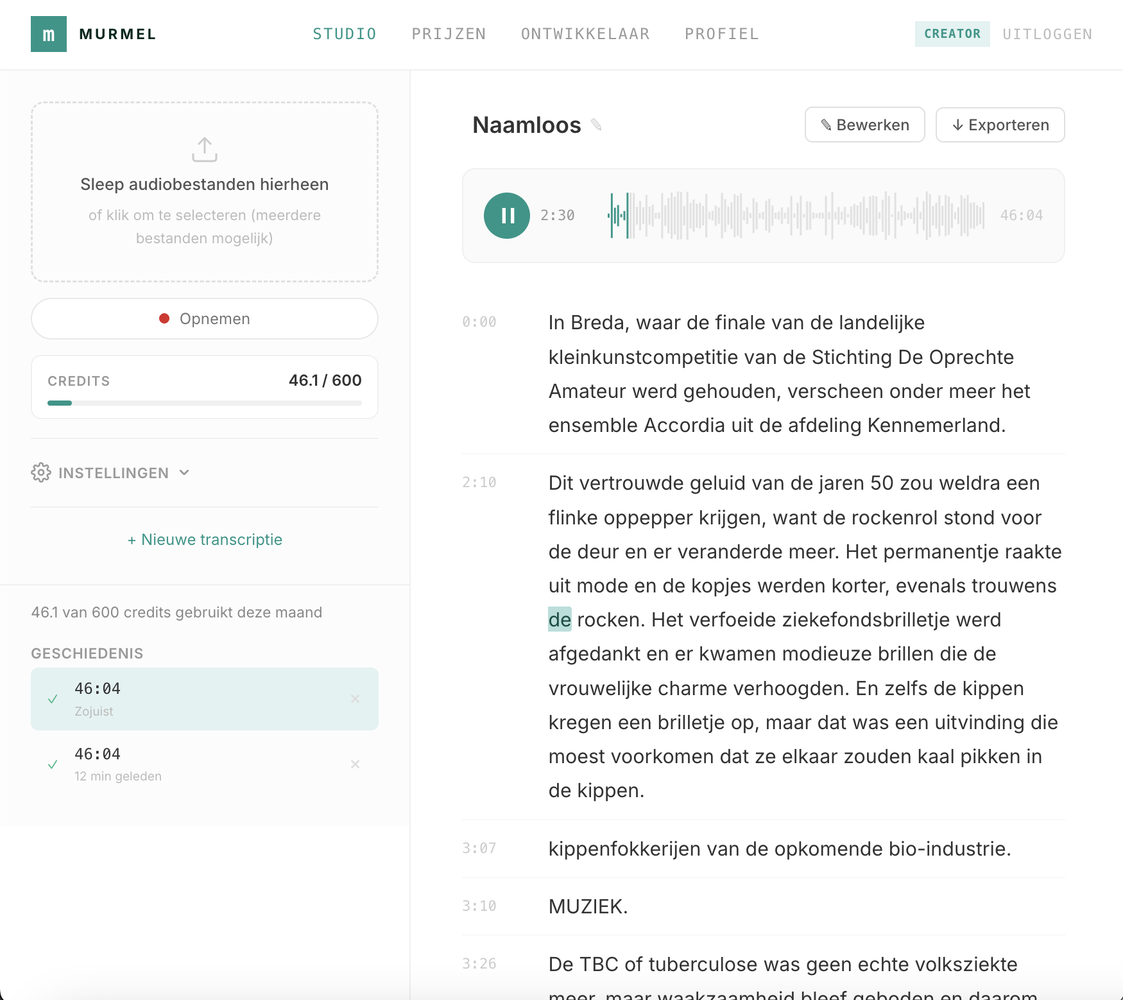
De interface ondersteunt alle veelvoorkomende audioformaten: WAV, MP3, M4A, WEBM, OGG, FLAC, en meer. Of je nu een vergadering transcribeert vanaf je telefoon of een hoogwaardig studiobestand, het werkt gewoon.
Je kunt het transcript direct lezen in de interface, of exporteren in een van de formaten hieronder (TXT, SRT, VTT, RTF, PDF, JSON, CSV).
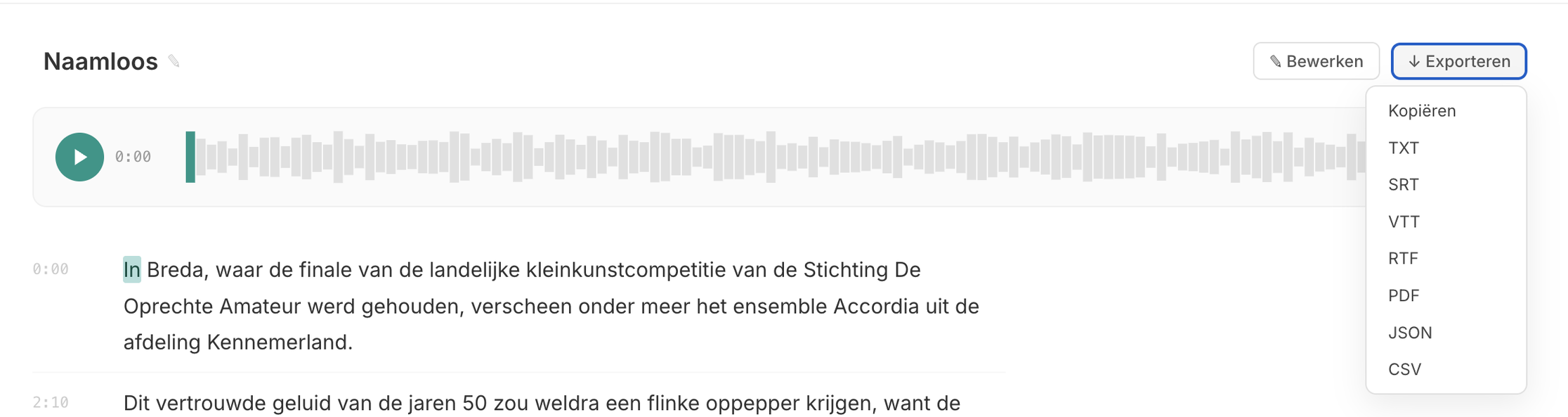
Voor organisaties die audio moeten transcriberen maar geen development team hebben, is dit de snelste weg. Upload je bestand, lees het resultaat, en kopieer de tekst. Klaar. Murmel is zo gebouwd dat iedereen in je organisatie het kan gebruiken, niet alleen de IT-afdeling.
De REST API
Voor developers en teams die Nederlandse transcriptie (speech to text) direct in hun eigen systemen willen integreren, komt Murmel met een volledig gedocumenteerde REST API.
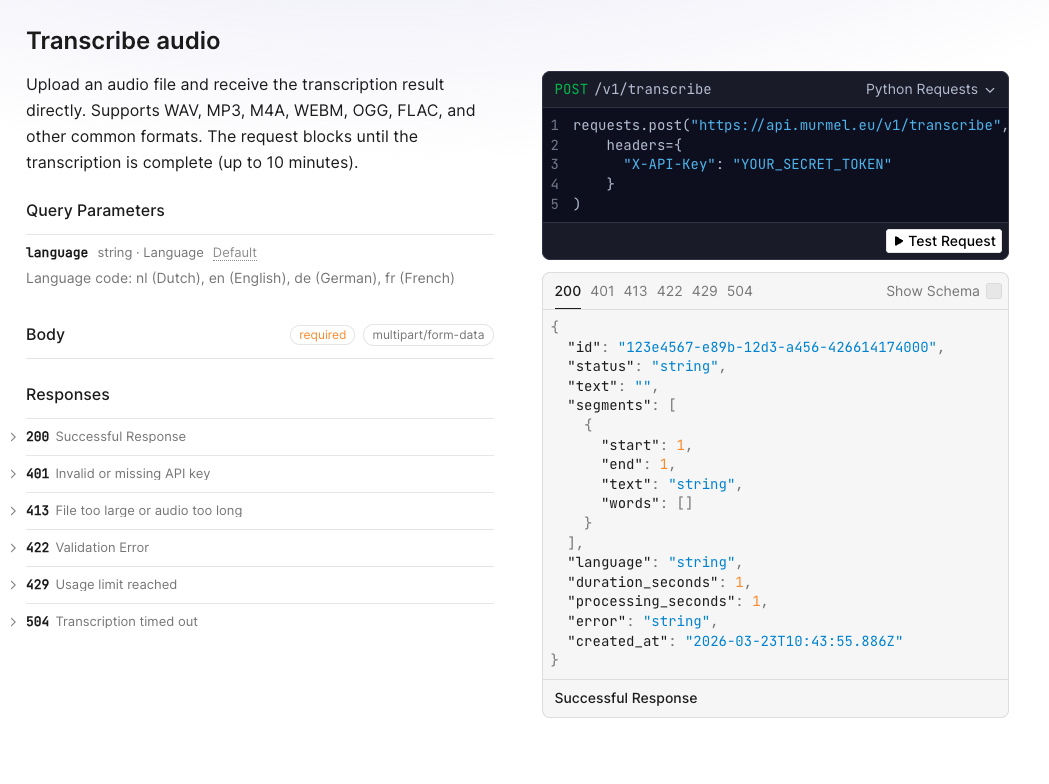
De API is rechttoe rechtaan: je stuurt de audio op en krijgt een transcriptie terug. Er zijn endpoints voor usage tracking, transcriptiegeschiedenis, en taalondersteuning. Alles is volledig gedocumenteerd met interactieve voorbeelden.
Typische use-cases waar we al interesse in zien:
- Simpel gebruik: Een bestand uploaden en een transcript terugkrijgen.
- Geautomatiseerde pipelines: Opnames van gemeenteraden die automatisch getranscribeerd worden direct na de sessie.
- Applicatie integratie: Transcriptie toevoegen als feature in bestaande software (zoals notulen software).
- Batch processing: Het schaalbaar transcriberen van complete archieven aan opnames.
- Quality assurance: Bestaande transcripties vergelijken en controleren met Murmel's output.
De API is ontworpen voor productie. Het verwerkt grote bestanden (tot 500 MB), retouneert woord-niveau timestamps voor exacte uitlijning, en ondersteunt synchrone transcriptie: je verstuurt de audio, en de response komt direct terug met het tekstresultaat.
De Python SDK
Voor de snelste integratiemogelijkheid hebben we een Python SDK gepubliceerd. Installeer het via pip en je schrijft code binnen enkele minuten:
from murmel import Murmel
client = Murmel(api_key="murmel_sk_...")
# Transcribe an audio file
result = client.transcribe("meeting.mp3")
print(result.text)Drie regels code om van audio naar tekst te gaan. De SDK neemt authenticatie, file uploads, error handling en retries uit handen. Het is beschikbaar via PyPI: pip install murmel.
Voor teams die transcriptie bouwen binnen hun applicaties, betekent dit dat je een werkend prototype kunt neerzetten in een middag, niet pas na weken sprinten.
100% Gehost in Nederland
Hierin is Murmel fundamenteel anders dan de concurrerende alternatieven.
Alle audioverwerking, de volledige data opslag, en alle model inference draait op infrastructuur die volledig in Nederland wordt gehost (EU-hosted). Jouw audio data verlaat dus nooit het land.
Voor veel organisaties is dit geen voorkeur, maar een harde vereiste. De nieuwe EU AI Act introduceert strenge verplichtingen over AI-systemen die persoonsdata verwerken. Ook vereist de AVG uiterste zorgvuldigheid rondom hoe audio wordt verwerkt. Als je gemeenteraadsvergaderingen, medische consulten, gerechtelijke stappen of HR-interviews transcribeert, vereist de vraag "waar gaat mijn audio naartoe?" een keihard, duidelijk antwoord.
Bij Murmel is dat antwoord uiterst simpel: Nederland. Punt.
En er is meer. We hebben stricte dataretentie protocollen: standaard worden jouw data en de gegenereerde tekst nooit gebruikt voor modeltraining. Alle audio en transcripties zijn automatisch verwijderd na 7 dagen in de Studio onmgeving, of per direct wanneer je zelf de delete-operatie via de API of user interface triggert (do-not-save). Jij behoudt áltijd de volledige controle.
Dit is geen onopvallende footnote ergens diep in de algemene voorwaarden van Murmel; het is een core design principe. Ik ben ervan overtuigd dat je superieure AI-transcripties moet kunnen afnemen zónder compromissen als het gaat om data governance. Murmel levert hiervoor het bewijs.
Murmel is klaar voor test-partners
Momenteel draaien de tests met onze eerste partners op volle toeren en de eerste resultaten zijn veelbelovend. Murmel overtuigt met prestaties op real-world audio, terwijl we de infrastructuur op de achtergrond continu optimaliseren.
Ik wil echter nog verder kijken. Ik wil begrijpen op welke punten Murmel presteert tijdens alle soorten Nederlandse audio, over diverse domeinen, met iedere soort spreker.
Om deze reden zoek ik actief naar testpartners.
Wanneer jij, of je team werkt met Nederlands gesproken woord, kom ik graag in contact! Stuur me een bericht waar je het precies voor in theorie zou inzetten, dan ontvang je een dosis gratis transcriptie-credits in ruil voor je nuchtere en eerlijke feedback. Met name als je actief bent met de volgende onderwerpen komen we heel efficiënt verder als partners:
- 🏛️ Raadsvergaderingen (gemeenteraadsvergaderingen, commissievergaderingen)
- ⚕️ Medische consulten en spreekkamer opnames
- ⚖️ Juridische processen en rechtszaken (court recordings)
- 📞 Call center / klantenservice gesprekken
- 🎙️ Journalistieke verslaggeving, interviews en populaire podcasts
- 🏢 Interne (directie)vergaderingen en bedrijfspresentaties
- 📚 Onderwijs: colleges, webinars of school interviews
Neem gerust contact op of schrijf in; dan richt ik de veilige API- of Studio toegang handmatig voor je in. Geen verplichtingen, geen kleine lettertjes — puur en alleen het model verbeteren aan de hand van praktijkgerichte validatie.
Wat komt hierna?
Het platform gaat binnenkort over op de officiële release.
De focus ligt vanaf nu op het maken van Murmel tot een product waarop je kunt vertrouwen. Dat betekent in de eerste plaats veiligheid (duurzame, veilige infrastructuur, transparante data-governance). Ook stroomlijning speelt mee: een schone interface, kraakheldere API-documentatie, en integraties die soepel werken zonder wrijving. Tot slot staat performante doorvoersnelheid in de sterren geschreven: als we meer klanten onboarden, zullen we blijven investeren in rekenkracht zodat Murmel meegroeit met jouw workloads.
Aan de kant van het onderliggende ASR-taalmodel bevinden we ons eveneens in een nieuwe fase. Speaker diarization ("wie zei wat") is vol in de maak en wordt een van de eerstvolgende features die we toevoegen.
Schrijf je in
Maak een account en kom op de wachtlijst via the-ai-factory.com/murmel, om vroege toegang te bemachtigen tot de interface en API voordat we lanceren.
Of neem direct contact op als je organisatie Nederlandse audio heeft die getranscribeerd moet worden.
Murmel is gebouwd in Nederland 🇳🇱, gehost in Nederland, en gebouwd voor organisaties die eisen dat Nederlands goed gaat.