Nieuw: Murmel, een in Nederland gebouwd spraak-naar-tekst model
Drie weken geleden vergeleek ik de beste open-source spraak-naar-tekst modellen op Nederlandse audio van debatten in de Tweede Kamer.
Het resultaat was uiterst teleurstellend.
Geen van alle was daadwerkelijk goed in de Nederlandse taal.
Daarom besloot ik eigenhandig een Nederlands model te trainen.
Ik noem het Murmel — omdat het daarmee de doelstelling omvat om zelfs sprekers die binnensmonds praten (murmelen) nagenoeg vlekkeloos te verstaan.
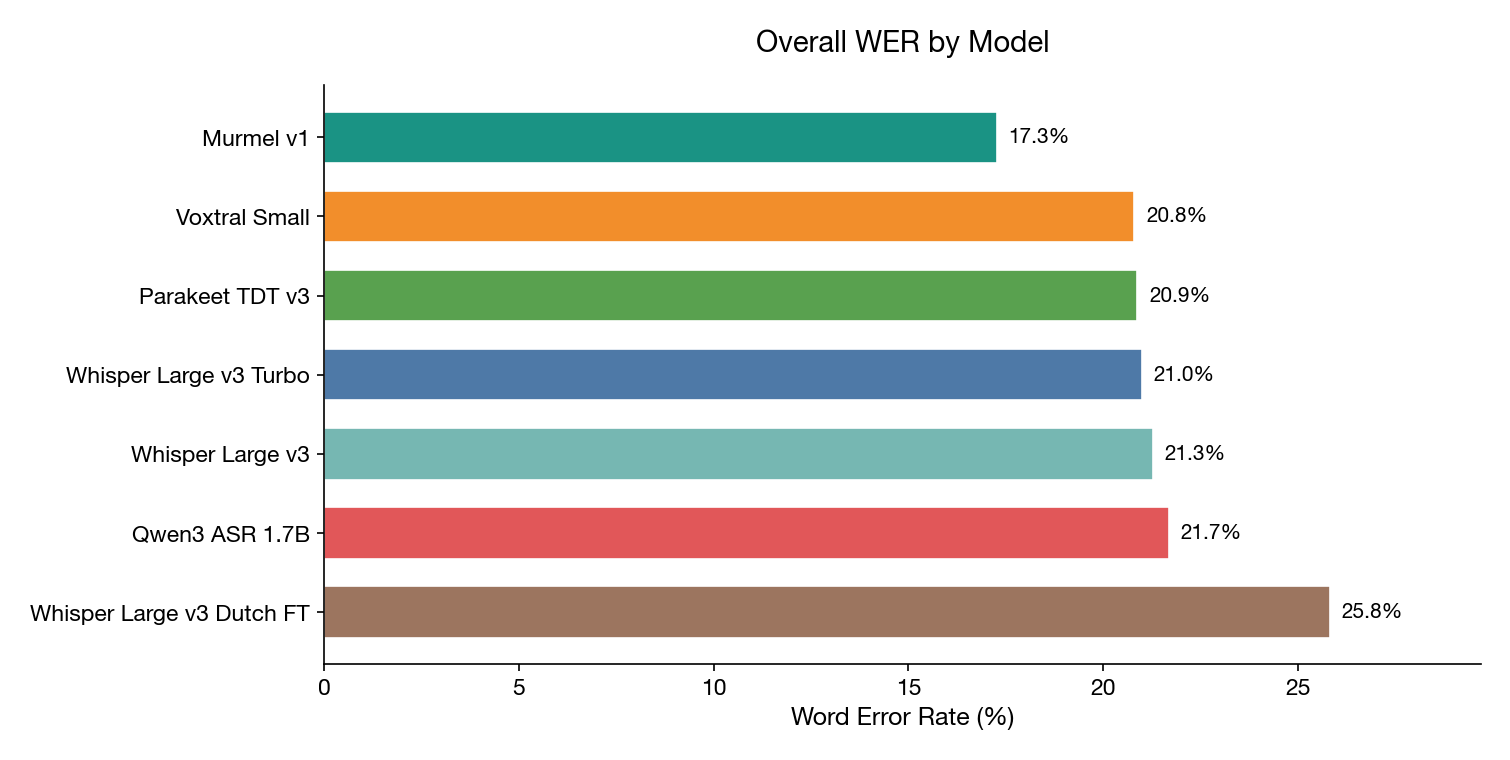
De eerste versie behaalt direct een indrukwekkende foutmarge van 17,3% en verslaat daarmee feilloos elk open-source alternatief op de markt.
Bij The AI Factory B.V. specialiseren we ons al vanaf de stichting in het bouwen van AI applicaties voor organisaties in Nederland. In combinatie met dat belangrijke werk ben ik actief bezig geweest met verzamelen en verwerken van nationale spraakdata om een perfect gelokaliseerd model te ontwikkelen. Het is tijd om de eerste resultaten te publiceren.
Van benchmarks naar training
De benchmark maakte vlot één fundamenteel ding duidelijk: er heerst een enorme potentie en ruimte voor een maximaal geoptimaliseerd model voor ons eigen taalgebied. Huidige generieke open-source motoren, doorgaans voornamelijk ingeladen met Engelse reeksen, behandelen het Nederlands altijd logischerwijs als een bijzaak. Ze zijn op sommige vlakken acceptabel, maar acceptabel is natuurlijk volstrekt onvoldoende als we complexe debatten in gemeenteraden, medische dossiers of strakke rechtszaken transcriberen. Sectoren waarin ieder individueel woord uitmaakt. Het is daarnaast de tijd dat in Europa en lokaal in eigen land een meer robuuste, soevereine AI geproduceerd wordt – ter afweer tegen de afhankelijkheid terzake de cloud systemen bij grote Big Tech spelers.
Gedurende het afgelopen jaar staken we zware investeringen in het creëren van die data basis die essentieel bleek ter fundatie. Deze exclusieve verzameling beslaat stilaan duizenden robuuste doordraaiende uren aan Nederlands: nieuwsuitzendingen, radioprogramma's en de brede publieke debatten via de nationale kanalen. Het omsluit daarmee heel Nederland binnen hoe het daadwerkelijk uitgesproken is in de praktijk: heel strak gepland door presentatoren tot the-fly onregelmatig spreektaal op straat; inbreng met non-native wortels over het polderlandschap tot de klassieke regionale accenten (uiteenlopend ver van de Randstad tot Groningen of Limburg).
De test resultaten in de actuele benchmark
Als we de nieuwste versie van Murmel positioneren tegenover exact diezelfde audio bron bestanden vanuit onze eerdere uitgebreide The AI Factory vergelijking, bereiken wij het uiterst indrukwekkende en solide percentage omtrent Word Error Rate op 17,3%. De bedoelde benchmark telt in theorie een absolute doorsnede qua weergave qua geluidsbestand en bestond uit 1.662 unieke geëxtraheerde stukken in circa 9 langdurige uren qua opnamen direct afkomstig vanuit de Tweede Kamer in actie. We elimineren en reduceren met deze getallen simpelweg aanzienlijk wat de gemaakte fouten was met een verschil grofweg één zesde ten opzichte van concurrentie, kijkende naar test winnaar van Mistral die aftopte als hoogst genoteerd met de vergelijking gezet destijds uitkomend 20,8% (Voxtral-small).
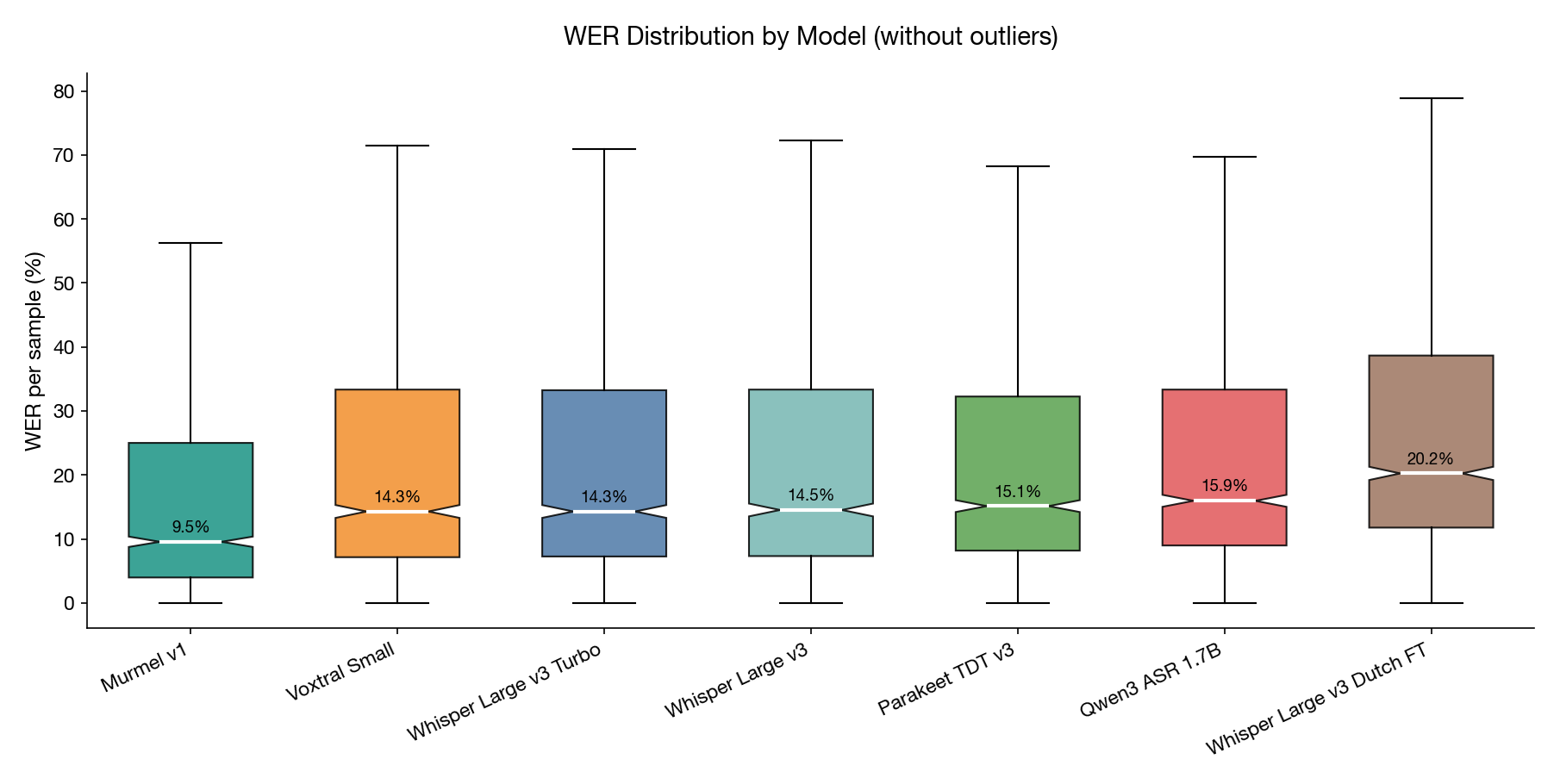
Word Error Rate (WER) per gekozen open-source variant, lage cijfers presteren logischerwijs beter.
Winnend in elke unieke subcategorie te vergelijken
De daverende overtuigingskracht wordt evident na inkijken op alle verplichte subcriteria en verdelingen op uitsplitsing in ons benchmark overzicht.
Vele resultaten bleven unaniem superieur aanwezig. Gedurende een pittige test in het vlotte interrumperen bij het Vragenuur bereikt Murmel nagenoeg de helft daling binnen het totaal aantal foute woorden en schiet die op 5,8%. Ter overweging zien we dat alle the alternatieven structureel struikelen rond of net over een moeizame of tragere uitslag.
Regionaal presteert het model tevens buitengewoon indrukwekkend: sprekers van ver uit Groningen noteren een flitsende 6,4% margin-of-errors (verschijnend the verhouding uit ten opzichte van concurrent de ranges dik dubbel in procent uitschieters tot The the range op 9,3% tot en met de 12 procent!). Dit bewijs rekt the volledige dataset standvastig the lang.
Uitzetting test op basis via the Word Error Rate verdelingsvorm (boxplots). Percentage the lager uitslaan staat beter.
Hardware en rekenkracht. Murmel is klaar voor gebruik
Hardware voor AI training is duur in Europa. De trainingsrondes voor dit model waren niet zo enorm lang als we initieel in gedachten hadden, en we hebben inmiddels alweer een veel grotere stapel uren extra data klaarstaan voor versie 2.
Echter, versie 1 is al ontzettend robuust en productieklaar voor transcriptie workloads in batches. Als de usecase erom vraagt, zijn we meer dan bereid om pijlsnelle hardware voor real-time streaming op te zetten.
Murmel is op zoek naar testpartners
Hier kun jij bij helpen. Ik ben actief op zoek naar organisaties die Murmel willen testen op hun eigen Nederlandse audio. Of dat nu gemeenteraadsvergaderingen, medische consulten, juridische procedures (inclusief het aanpassen aan domeinspecifieke woordenschat), opnames van callcenters of iets anders is, ik wil begrijpen hoe het model presteert in de dagelijkse praktijk.
Als je een probleem hebt met betrekking tot Nederlandse audio en een impactvolle use-case, neem dan contact op! Het is mogelijk om Murmel te draaien op jouw data via EU-infrastructuur (ontworpen voor grootschalige transcriptie), het te vergelijken met wat je momenteel gebruikt, en een eerlijke beoordeling te geven van waar het helpt en waar het nog tekortschiet. Voor organisaties in de publieke sector die navigeren rond de EU AI Act is EU-gehoste en controleerbare infrastructuur steeds vaker een harde eis in plaats van een voorkeur. Murmel is precies met dat in gedachten gebouwd.
Gebouwd in Europa, voor Europa, met Europa
Murmel is nog niet perfect, en er is nog betekenisvol werk te verrichten. Maar de richting is duidelijk: een doelgericht Nederlands model presteert beter dan elk algemeen alternatief, en deze kloof zal alleen maar groeien.
Nederlands is de eerste halte voor Murmel. Maar exact hetzelfde probleem bestaat voor het Duits, Frans, Pools en elke andere Europese taal die als tweedeklas wordt behandeld door modellen die primair op het Engels zijn getraind.
Nederland heeft AI-talent van wereldklasse. Het wordt hoog tijd dat we ook Nederlandse AI van wereldklasse hebben. Als je werkt met Nederlandse audio, gemeenteraadsvergaderingen, medische consulten, opnames van het callcenter, juridische procedures, of alles daartussenin: meld je aan op de wachtlijst via the-ai-factory.com/murmel om vroege toegang te krijgen tot de interface en de API, of neem contact op als jouw organisatie Murmel wil testen op data uit de praktijk.